
학습목표
- 스레드풀과 이벤트 루프에 대해 이해한다.
목차
- 동시성 처리개념
- 스레드 풀의 구조 및 활용
- 비동기 처리개념
- 이벤트루프 구조 및 활용
- completable future
들어가기 전..
1. 이어지는 게시글 반복 학습하기 !
[대규모트래픽 이론] #1.1 동시성 처리와 비동기 처리의 기본 개념
학습목표동시성, 비동기 처리의 개념을 이해하고 구분할 수 있고, 그 예시들을 적용해본다.목차동시성 및 비동기 처리 기초 개념 동시성 및 비동기처리를 위한 기본 구조들어가기 전...동시성과
dev-rosiepoise.tistory.com
동시성(Concurency) 처리 개념
- 동시성은 여러 작업이 동시에 진행되는 것처럼 보이도록 설계된 시스템
- 실제로는 대부분의 경우 단일 코어에서 여러 작업이 분할되어 교차로 처리
- 사용자는 각 작업이 동시에 실행되는 것처럼 느낌
- 멀티스레딩을 통해 각 작업을 독립적으로 실행 가능 (Java - mulit thread로 구현가능)
스레드 풀(Thread Pool)이란?
- 미리 생성된 스레드의 집합으로, 작업이 들어올때마다 새로운 스레드를 생성하는 대신, 이미 생성된 스레드를 재사용하여 작업을 처리
- 스레드 풀을 사용하면 스레드 생성 및 소멸에 따른 오버헤드를 줄일 수 있어, 동시성 차원에서 자원을 효율적으로 관리
스레드 풀의 구조 및 특징
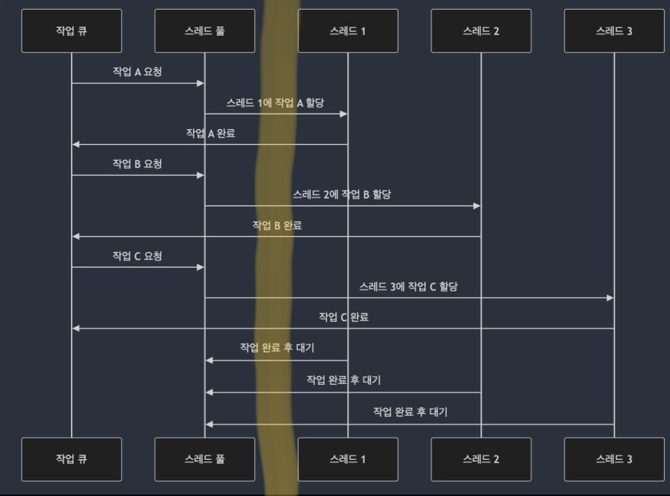
- 스레드 풀은 여러 작업을 동시에 처리하기 위해 미리 생성된 스레드 집합을 유지
- 이때, 적절한 크기를 설정하는 것이 중요! 너무 작으면 처리량이 제한되고, 너무 크면 메모리, cpu를 과도 사용하기 때문
- 스레드 풀에 작업을 제출하면, 해당작업이 스레드 풀의 사용 가능한 스레드에 할당
- 스레드가 작업을 마치면, 그 스레드는 다른 작업에 할당되기 전까지 대기 상태
Java의 Excutors API를 통한 스레드 생성 및 관리
public class ThreadPoolExample {
public static void main(String[] args){
// 3개의 스레드로 구성된 고정된 스레드 풀 생성
ExecutorService excutor = Executors.newFixedThreadPool(3);
for(int i=1; i <= 5; i++){
final int taskID = i;
excutor.submit(()->{
System.out.println("task "+taskID + " is running in thread" + Thread.currentThread().getName());
});
}
}
}
결과
task 2 is running in threadpool-1-thread-2
task 1 is running in threadpool-1-thread-1
task 3 is running in threadpool-1-thread-3
task 4 is running in threadpool-1-thread-2
task 5 is running in threadpool-1-thread-2;
장점 : 고정된 크기의 스레드를 미리 생성함으로써, 스레드 생성 비용을 줄이고 자원을 보다 효율적으로 사용
스레드 풀을 사용할 때, 자원을 효율적으로 사용하려면 어떤 요소를 고려해야 할까?
- 스레드 풀의 크기
- 너무 많으면, thread cotext 스위칭 비용이 높아지고, 시스템 성능저하의 가능성
- 너무 적으면, cpu 자원이 충분히 활용되지 않을 가능성. cpu core수와 작업 특성을 고려하여 최적의 thread 결정
- 작업의 종류
- cpu 집약적 - thread를 cpu 크기에 맞추는게 유리
- i/o 집약적 - 스레드 대기시간이 많아 더 많은 스레드를 할당하여 대기시간에 다른 작업을 처리
- 스레드 생성과 파괴의 비용
- 스레드 풀 설정을 통해 최소, 최대 스레드수를 조절하여 스레드풀 동적 관리
- 동기화 문제
- 여러 스레드가 공유 자원에 접근시, 동기화 문제 발생 가능성을 고려
- 동기화 매커니즘 사용시 성능저하 가능성이 있기에 가능한 lock경쟁을 최소화
- 응답시간과 처리량
- 특정 어플리케이션 요구사항을 최적화 - 빠른 응답이 중요한 경우, 스레드수를 늘리고 대기시간을 줄인다
비동기 (Asynchronous Processing) 처리 개념
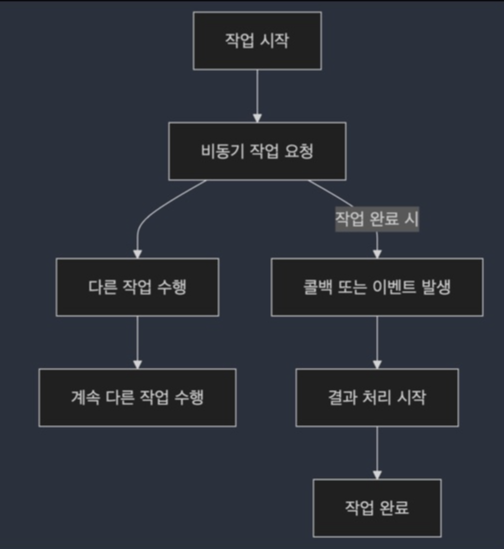
- 비동기 처리는 특정 작업이 완료될 때까지 기다리지 않고 다른 작업을 계속 진행할 수 있는 처리 방식
- 이는 작업이 완료될 때까지 대기하지 않기 때문에, 시스템은 그동안 cpu 자원을 다른 작업에 할당할 수 있음
- 작업이 완료되면 콜백이나 이벤트를 통해 결과를 알리고, 그 결과에 대한 추가 작업이 수행
비동기 처리와 이벤트 루프 : 이벤트 루프 (event loop)

- 이벤트 루프는 비동기 처리를 위한 구조로, 하나의 스레드가 여러 작업을 순차적으로 처리하는 방식
- 입출력 작업에서 매우 효과적
- 이벤트 루프는 단일 스레드 기반으로 동작하여, 비동기 작업이 완료될 때마다 이벤트 큐에 있는 작업을 처리
Java의 비동기 이벤트 루프
public class EventLoopExample {
public static void main(String[] args){
try{
Path filePath = Paths.get("계약이행현황.txt");
AsynchronousFileChannel fileChannel = AsynchronousFileChannel.open(filePath);
ByteBuffer buffer = ByteBuffer.allocate(1024);
Future<Integer> result = fileChannel.read(buffer, 0);
while (!result.isDone()){
System.out.println("file is being read asynchronously!!");
}
System.out.println("read "+result.get() + "bytes from teh file");
}catch (Exception e){
e.printStackTrace();
}
}
}
결과
file is being read asynchronously!!
file is being read asynchronously!!
...
file is being read asynchronously!!
file is being read asynchronously!!
read 541bytes from teh file
=> 하나의 스레드로 많은 비동기 작업을 수행할 수 있다. 그러나 cpu 집약적인 작업에서는 이벤트 루프는 단일 스레드이기 때문에 cpu 부하가 큰 작업에서 비효율 적이다.
이벤트 루프가 입출력 작업에 왜 적합할까?
- 논블로킹 I/O 모델
- 즉시 다음작업으로 넘어가기 때문에 시스템의 작업능력이 향상
- 효율적인 자원 사용
- 네트워크 요청후 응답대기후 다른 작업이 가능
- 반응성 유지
- 사용자 입력후 네트워크 요청에 빠르게 반응이 가능하며 실시간 반응해야하는 application에 적절
Java 비동기 API 디자인 패턴
1. 콜백 패턴
public class CallbackExample {
public static void main(String[] args){
asyncOperation(result->{
System.out.println("결과 :"+result);
});
}
private static void asyncOperation(Callback callback) {
new Thread(()->{
try{
// 작업 시뮬레이션
Thread.sleep(9000);
callback.onComplete("작업 완료");
}catch (Exception e){
e.printStackTrace();
}
}).start();
}
}
- 콜백함수는 비동기 작업이 완료된 후 실행될 작업을 미리 등록해 두는 방식
- 단순하고 효율적이지만, 콜백 지옥이라 불리는 복잡한 구조가 될 수 있음
2. CompletableFuture
import java.util.concurrent.CompletableFuture;
public class CompletableFutureExample {
public static void main(String[] args){
CompletableFuture<Void> future = CompletableFuture.supplyAsync(()->{
try {
//비동기 작업 시뮬레이션
Thread.sleep(9000);
}catch (InterruptedException e){
e.printStackTrace();
}
return "작업 완료";
}).thenApply(result->{
System.out.println("결과 :"+result);
return result +" - 후속 작업 완료";
}).thenAccept(System.out::println);
future.join(); // 또는 future.get(); 예외 처리가 필요
}- 비동기 작업의 결과를 비동기적으로 처리할 수 있는 java의 강력한 api
- javascript의 promise와 유사하며, 비동기 작업이 완료되면 그 결과를 사용해 후속 작업을 정의 가능
예외로,
-> 이거 테스트하다가, 원래는 내가 기대한 결과가 결과: 작업완료, 결과 - 후속 작업 완료 이었는데 콘솔에 안찍혀서 뭐지? 해서 구글링 + 지피티 선생님에게 물어봄.
자바의 main() 메서드는 비동기 작업이 완료되기 전에 종료될 수 있습니다.
즉, CompletableFuture는 백그라운드 스레드에서 실행되는데, main() 스레드가 그걸 기다리지 않고 먼저 종료되면 출력도 못 보고 끝나버림 이를 해결하기 위해 아래와 같이 조언을 줌
✅ 해결 방법 1: get() 또는 join() 사용
- CompletableFuture는 비동기이므로 메인 스레드가 먼저 종료될 수 있다.
- 결과를 보거나 유지하려면 join() 또는 get()으로 명시적으로 기다려줘야 한다.
- 마지막 체인에 .join()을 붙이면 전체 흐름을 기다릴 수 있어 좋음.
해서,
future.join() 을 작성함. 근데 내가 원래 string 반환으로 작성했는데 왜 void로 반환시키라는 거임 .. 왜죠 .. 이해안감
다시 지선생님에게 물어봄
| 1단계 | supplyAsync() | CompletableFuture<String> → "작업 완료" |
| 2단계 | thenApply() | CompletableFuture<String> → "작업 완료 - 후속 작업 완료" |
| 3단계 | thenAccept() | 🔥 CompletableFuture<Void> |
바로 이 thenAccept() 때문에 최종 체인의 타입이 CompletableFuture<Void>가 되는 것입니다!
🔍 왜 thenAccept()는 Void를 반환하나요?
thenAccept()의 역할은:
- 이전 결과를 받아서 (thenApply에서 전달된 String)
- 그걸 그냥 소비만(consume) 하고, 새로운 값을 반환하지 않습니다.
즉, 마지막 단계는 출력만 하고 끝, 새로운 값은 없으니 리턴형이 Void가 되는 거예요.
아,, thenAccept()는 소비만 하고 새로운 값을 반환하지 않아서, void로 반환해야함!!! tmi는 일단 딴길로 샐수 있으니 여기까지.
참고, 강의 및 구글링
1티어 패션 커머스의 세일 도메인 프로젝트로 배우는 대규모 트래픽을 견디는 실전 백엔드의 모
실전 대용량 트래픽 처리의 모든 것! 대규모 시스템 설계부터 기능 구현, 테스트까지!
fastcampus.co.kr
'대용량 시스템 > 대규모 트래픽 이론' 카테고리의 다른 글
| [대규모트래픽 이론] #3.1 대규모 트래픽 처리 개요 (0) | 2025.04.06 |
|---|---|
| [대규모트래픽 이론] #2.3 비동기 처리 시스템의 장단점 및 사례 (0) | 2025.04.06 |
| [대규모트래픽 이론] #2.2 비동기 메시징 시스템 이해 (0) | 2025.03.30 |
| [대규모트래픽 이론] #2.1 비동기 처리 아키텍처 이해와 확장 (0) | 2025.03.29 |
| [대규모트래픽 이론] #1.1 동시성 처리와 비동기 처리의 기본 개념 (0) | 2025.03.11 |